by the MaSHEne Learners
Our project aims to promote inclusivity in the beauty industry through the use of deep learning algorithms to create more representative and realistic beauty filters. We developed a deep-learning-based process that can be used to create inclusive filters that accurately represent diverse features and skin tones. We utilized a diverse dataset of 50 faces, each composed of 10 individuals from the five races identified by the government department of the National Center for Education Statistics (NCES), in conjunction with Generative Adversarial Networks (GANs). By training deep-learning algorithms on a diverse set of skin tones, we demonstrated that it is possible to facilitate the development of filters that accurately detect and incorporate a variety of skin tones. Our approach is designed to be accessible and easy to use, allowing anyone to create filters that represent a range of skin tones and features. By providing this tool, we hope to encourage the creation of more inclusive beauty filters that accurately reflect the diversity of our society and challenge the Western beauty standard.

Contributors: Lanzhen Wang, Natia Lollie, Leta Ames, Nabila Mohamed, Ashley Lewis
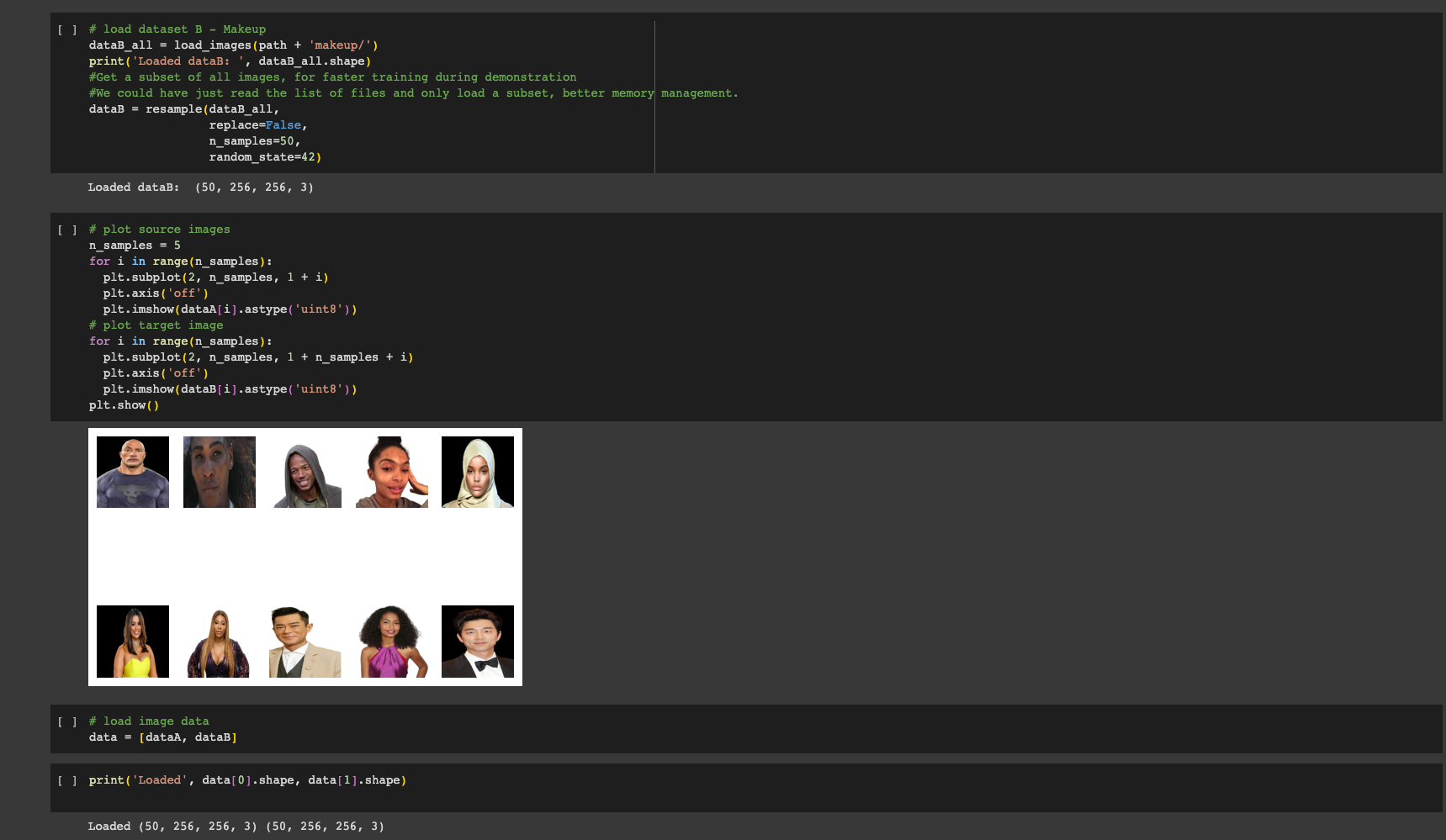
We used cycleGANs (Cycle-Consistent Generative Adversarial Network) and a diverse dataset of 50 faces that featured a wide range of skin tones to develop a process for creating filters that seamlessly enhances the user’s appearance in real time without diminishing performance across skin tones.
Capstone Video:

Google Colab Code:
Capstone Report:

Capstone Powerpoint:
Moving forward our aim is to focus on improving the training dataset. One way to achieve this is to increase the size of the dataset to include more diverse images. This would provide our model with more information to train and help us include images of people with further variation in age, weight, facial features, etc. It would be best to expand the dataset to include images of people who are not public figures. We also need to include images of people from different angles to prepare the model better for real-world applications.
Our team was able to observe the success of our model in generating images with makeup from images without makeup, despite the unpaired nature of our data. This was aided by utilizing images of the same individuals with and without makeup, which allowed the model to make subtle changes to their appearance. Our generated images showed an increased smoothness in the skin, but did not consistently alter skin tone.
Individual recognition and achievement recieved on Samsung's global and USA newsrooms for my work within their A.I. and M.L. campus.
View on Social Media